
(снимка: arxiv.org/University of California, Berkeley)
Американски учени разработиха система, която разпознава тихата реч и я превръща в звукова, използвайки невронна мрежа. В бъдеще системата може да се използва за създаване на слушалки, които позволяват на хората да говорят по телефона, без да издават никакви звуци.
[related-posts]
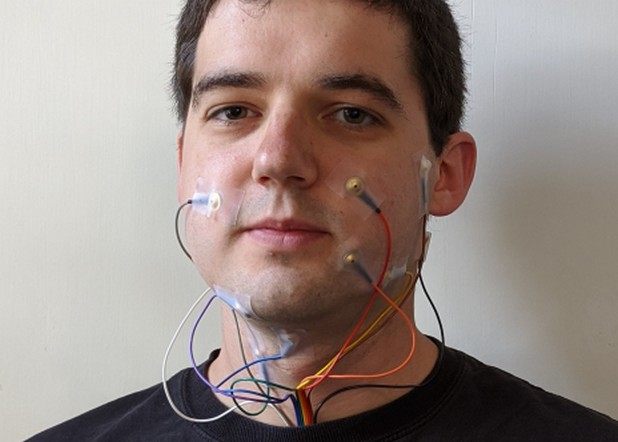
Въпреки че, когато говорим на „себе си”, не изричаме думи на глас и не издаваме никакви звуци, мозъкът все пак принуждава мускулите на гласовия тракт да се движат, макар и много по-малко, отколкото при „нормална” реч – този процес се нарича субвокализация. Инженерите могат да разчитат мускулните контракции по различни начини – главно с помощта на електромиография (EMI), която записва електрическата активност на мускулите с помощта на електроди, поставени на врата и лицето.
Съществуващите интерфейси за разпознаване на субвокализации могат да преобразуват мълчалива реч само в текст, но учените от Калифорнийския университет в Бъркли са разработили алгоритъм, който е способен да „озвучава” мускулни контракции. Той е обучен на три вида данни – записи на звукова реч и мускулна активност по време на звукова и нечуваема реч.
Алгоритъмът отчита три сигнала – две електромиограми и звукова реч. На първия етап той намира оптимално съответствие между два сигнала – звукова и нечуваема реч, а на втория, използвайки получените данни, създава аудиозапис на реч от електромиограма, тоест нечуваема реч от аудиозапис на звукова реч. Такъв алгоритъм е необходим за обучение на невронна мрежа, която прави същото, като приема не три вида сигнали като вход, а само един – електромиограма на нечуваема реч.
Учените са използвали невронна мрежа с краткосрочна памет, като получените данни от нея са предавани на невронна мрежа WaveNet, която ги декодира в аудио запис на човешки глас. За обучение е използван 20 часа запис на звукова и нечуваема реч, представен под формата на три вида данни. След обучението разработчиците проверявали разбираемостта на генерираните записи.
Като метрика учените са използвали стандартната вероятност за грешка – сумата от променени, липсващи и допълнителни думи, разделена на общата дължина на текста. За прости фрази като дати и други числа вероятността за грешка на пълноценна невронна мрежа е 3,6, а за такава, която се обучава само в звукова реч, е 88,8. За сложни фрази като откъси от книги разликата не е толкова голяма: 74,8 до 95,1 при проверка от човек и 68 до 91,2 при проверка от системата за разпознаване на реч Mozilla DeepSpeech.



2 коментара
Да, само трябва да се подберат подходящи обекти за този експеримент.
Персонажи стил Луи дьо Фюнес.
И тихи разговори с духа ни.
Който иска да пише, при наличието на инвеститори естествено или пък за славата си, може да намери толкова сюжети в Технюз, въпрос на твореска личност и интелект.
Тези теми са интересни и точно затова ги чета.
tova se znae otdavna i mnogo drugi neshta i tankosti ima