
(снимка: Google)
Google разработва собствени ускорители за машинно обучение отдавна – още през 2017 г. се появи модулът TPU, способен бързо да умножава матрици 256×256. Третата версия на TPU постави редица рекорди в областта на обучението на невронни мрежи, а сега интернет компанията представя TPU v4 като най-бързия ускорител за изкуствен интелект.
Не всеки ще се съгласи с тази формулировка, тъй като публикуваните резултати от теста ML Perf 0.7 могат да се тълкуват малко по-различно. Така например, Nvidia твърди, че най-бърз от предлаганите на пазара е суперкомпютърът, базиран на нейния ускорител A100, докато Google използва в тестовете все още необявен официално ускорител TPU v4.
Системите за изкуствен интелект стъпват или на вече обучени невронни мрежи, или на такива в процес на обучение. Във втория случай са необходими в порядък повече изчислителни ресурси, което предполага използване на мощни многоядрени системи. За оценка на производителността на системите често се използва набора от тестове MLPerf.
В основата на системата-рекордьор TPU v3 на Google стояха модули Cloud TPU Pod, като всеки от тях съдържаше повече от 1000 чипа Google TPU и достигаше производителност от над 100 Pflops. Основният конкурент Nvidia също обръща много сериозно внимание на AI ускорителите. Дори базираните на V100 решения лесно се конкурираха с TPU v3, а най-новият A100, базиран на архитектура Ampere, демонстрира още по-високи нива на производителност в теста MLPerf Training.
Google Research обаче публикува резултати от нов тест с MLPerf Training 0.7, който се базира на все още предстоящите да излязат математическите копроцесори TPU v4. Съперничеството с A100 е доста интересно – при някои сценарии Nvidia се оказва по-бърза, но в други технологията на Google има превес.
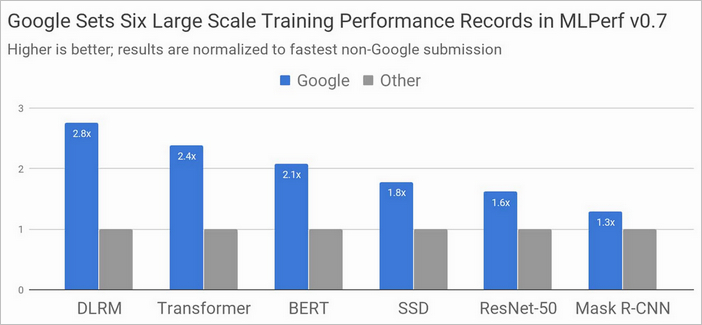
Nvidia, от своя страна, отчита 16 рекорда с новия си ускорител DGX A100 и подчертава, че нейните продукти вече се достъпни за покупки (и изпълняват всякакви ML Perf тестове или реални натоварвания), докато резултатите на конкурентите често са или непълни или получени на хардуер, който е експериментален или не може да се придобие в момента.
При тестовете на Google са използвани реализации на AI модели в TensorFlow, JAX, PyTorch, XLA и Lingvo. Четири от осемте модела са „обучени” за по-малко от 30 секунди, което е много впечатляващ резултат. За сравнение, през 2015 г. на съвременния по онова време хардуер подобен процес на обучение би отнел повече от три седмици. Като цяло, TPU v4 обещава да е 2,7 пъти по-бърз от TPU v3.
Подробна информация за тестовете с MLPerf 0.7 е публикувана в официалния блог на Google Cloud, наред с подробности за базирани на TPU системи, но все още ограничени до третата версия на чипа. Засега е известно, че четвъртото поколение TPU е повече от два пъти по-бързо в операциите за умножение на матрица, има по-бърза подсистема на паметта и подобрена система за взаимосвързване.


